
Overview
When deploying a model. The files will be splited into 2 different "database".
- 📁 Scenario Database (S3)
- This is what allow us to have and create different scenarios in the web application.
- Those are the files a user can change in the web application.
- 🐳 Docker container (ECR).
- those files are non editable by a user in the web application
- every scenario will inherit those files.
When a scenario is run on the cloud (Lambda), They will be merge (see below)
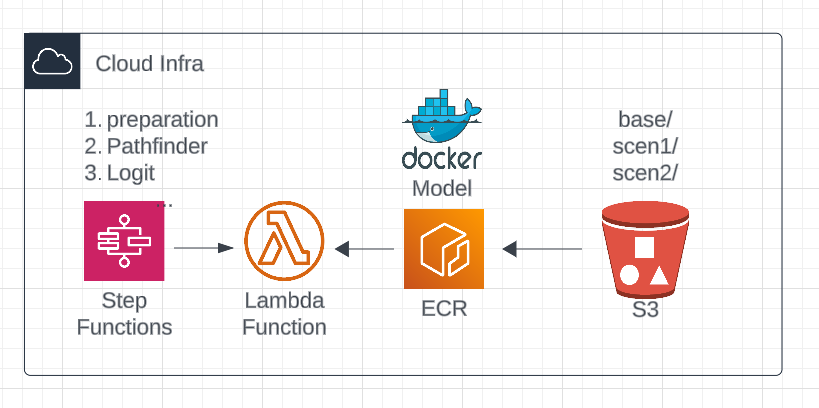
INFO
the step function defines which notebook to run in which order
Local model File Structure
The reccomanded file structure for a model is display bellow. It contains scenarios folder to mimic the scenario structure we will have on the cloud.
.
├─ inputs
│ ├─ calibration
│ | └─ ...
│ ├─ parameters.xlsx
│ └─ ...
├─ notebooks
│ ├─ 1_preparation
| | ├─ B10_network_preparation.ipynb
│ | └─ ...
│ ├─ 2_model
│ | └─ ...
│ └─ 3_model
│ └─ ...
├─ ...
| └─ ...
├─ scenarios
| ├─ base
| | ├─ inputs
| | | ├─ pt
| | | | ├─ links.geojson
| | | │ └─ nodes.geojson
| | | ├─ road
| | | | ├─ road_links.geojson
| | | │ └─ road_nodes.geojson
| | | ├─ od
| | | │ └─ od.geojson
| | | ├─ params.json
| | │ └─ ...
| | ├─ model
| | │ └─ ...
| | ├─ outputs
| | └─ styles.json
│ └─ ...
├─ DockerFile
├─ Dockerfile.dockerignore
├─ requirement.txt
├─ .env
└─ step-functions.json
...Scenarios (S3)
Scenarios Are the collection of files that are editable in the webapp. We use the same file structure for the local developpement and the deployed Database.
Note
it is the exact same structured found when we export a scenario into a .zip file in the web app.
├─ base
| ├─ inputs
| | ├─ pt <-- PT network editable in the app
| | | ├─ links.geojson
| | │ └─ nodes.geojson
| | ├─ road <-- road network editable in the app
| | | ├─ road_links.geojson
| | │ └─ road_nodes.geojson
| | ├─ od <-- OD's editable in the app
| | │ └─ od.geojson
| | ├─ params.json <-- editable parameters for the model // [!code highlight]
| │ └─ ...
| ├─ model <-- hidden in the app. zippedPickle of the model // [!code highlight]
| │ └─ ...
| ├─ outputs <-- results viewable in the app // [!code highlight]
| └─ styles.json <-- styles preset for the map result page. // [!code highlight]
└─ ... <-- any other inputs not editable in the app. // [!code highlight]
...Docker Container (ECR)
Any other files will be store in the Docker container with Quetzal, the notebooks and the python librairies. We are generally talking about the inputs folder.
.
├─ inputs
│ ├─ calibration
│ | └─ ...
│ ├─ parameters.xlsx
│ └─ ...
├─ notebooks
│ ├─ 1_preparation
| | ├─ B10_network_preparation.ipynb
│ | └─ ...
│ ├─ 2_model
│ | └─ ...
│ └─ 3_model
│ └─ ...
├─ ...
| └─ ...Execution (Lambda)
When running a scenario on the cloud platform. The files of the selected scenario will be copy into the model root directory during execution.
Files coming from the Docker container
Editable Files coming from the selected scenario on the Database (S3)
├─ inputs
│ ├─ calibration
│ | └─ ...
│ ├─ parameters.xlsx
│ └─ ...
| ├─ pt
| | ├─ links.geojson
| │ └─ nodes.geojson
| ├─ road
| | ├─ road_links.geojson
| │ └─ road_nodes.geojson
| ├─ od
| │ └─ od.geojson
| ├─ params.json
│ └─ ...
├─ model
│ └─ ...
├─ outputs
└─ styles.json
└─ ... Note
files from scenario (S3) have priority and will overwrite the one on docker if the have the same name.
important
We need specific headers in our notebooks to take this into account. when running locally, we need to specify which scenario we want to run. But when running on the cloud, the scenario is already selected (see below)
Notebook Headers
Like when using a Quetzal Launcher, The notebooks are converted into .py files and args are passed to them when running on the Cloud (lambda)
Use those headers in your notebooks:
import sys
import json
default = {'scenario': 'base', 'training_folder':'../..'} # Default execution parameters
manual, argv = (True, default) if 'ipykernel' in sys.argv[0] else (False, dict(default, **json.loads(sys.argv[1])))# Add path to quetzal
sys.path.insert(0,'../../../../quetzal/')
from quetzal.model import stepmodel
from quetzal.io import excel
import os
on_lambda = bool(os.environ.get('AWS_EXECUTION_ENV'))There is a env variable when running in the cloud AWS_EXECUTION_ENV that we can use.
scenario = argv['scenario']
training_folder = argv['training_folder']
# if local. add the path to the scenario scenarios/<scenario>/
local_scen_path = '' if on_lambda else os.path.join('scenarios/', scenario)
input_folder = os.path.join(training_folder,'inputs/')
scenario_folder = os.path.join(training_folder, local_scen_path, 'inputs/')
model_folder = os.path.join(training_folder, local_scen_path, 'model/')
output_folder = os.path.join(training_folder, local_scen_path, 'outputs/')If locally or on the cloud (lambda). the paths will differ
| Local | Cloud | |
|---|---|---|
| input_folder | ../../inputs/ | ../../inputs/ |
| scenario_folder | ../../scenarios/base/inputs/ | ../../inputs/ |
| model_folder | ../../scenarios/base/model/ | ../../model/ |
| output_folder | ../../scenarios/base/outputs/ | ../../outputs/ |
Finally. The parameters in the web interfaces are passed through the argv. You can update the parameters.xlsx like this:
var = excel.read_var(file=input_folder+'parameters.xlsx', scenario=scenario, return_ancestry=False)
if 'params' in argv.keys():
var.update(pd.DataFrame.from_dict(argv['params'], orient="index").stack())TIP
The outputs folder may not exist on the Cloud. Make sure to create it before exporting a file to it!
Important
please make sure to always use those variables (input_folder, output_folder, etc.) when reading and writing files.